ElasticSearch
1.简介
ES是基于Lucene的高扩展的分布式搜索服务器,支持开箱即用。
优势:
- 扩展性好,可部署上百台服务器集群,处理PB级数据。(1PB = 1024TB)
- 索引数据、搜索数据速度非常快,接近实时。
- 支持全文检索、结构化搜索、数据分析、复杂语言处理等。
- 更适合查多改少的情景。
2.与Lucene关系
- Luncene是一个库。使用它需要使用Java语言集成在应用中,Lucene非常复杂,需要深入了解检索相关知识来理解它的工作。
- ES使用Java开发,以Lucene为核心来实现所有的索引和搜索功能。用简单的Restful接口隐藏Lucene的复杂度。
3.工作原理
ES使用了有限状态转换器实现了全文检索的倒排索引,实现了用于存储数值数据和地理位置数据的BDK树,以及用于分析的列存储。
ES不支持事物,默认将所有的字段全部建立索引。
向 Elasticsearch 中存储数据,其实就是向 es 中的 index 下面的 type 中存储 json 类型的数据。
当ES节点启动后,会利用多播寻找集群的其他节点,并与之建立连接。
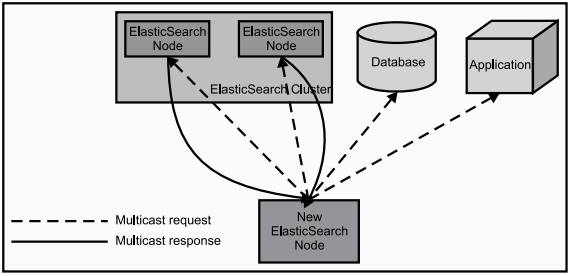
ES中,存储数据的基本单位就是索引。
案例:ES中存储订单系统的销售数据,就在ES中创建了一个索引(order-index),所有销售数据都在该索引中,一个索引就像数据库,type(类型)相当于一张表,一个index会有多个type;mapping相当于表的结构定义,定义了什么字段类型,往index中的一个type加一行数据就叫做一个documnet,每个document有多个filed,每个filed代表一个字段的值。
4.核心概念
集群(cluster)
在ES中,集群是由一个或多个ES节点组成的,每个集群都有一个唯一的名称/标识符,用作节点加入集群的依据。
每一个集群中有一个Master节点,若是这个Master节点挂了,集群可以用其他的节点代替。 在ES中还支持跨集群复制、跨集群检索等等功能
实例和节点(Instances and Nodes)
节点也就是运行的ES实例,它隶属于某一个集群。假设当我们启动一个节点想加入已经存在的一个集群中时,可以在配置文件中配置该集群的名称,以及通信的ip + port,ES会自动通过“单点传送”的方式来自动发现集群并尝试加入这个集群。
节点分为下面几种类型:
- Master-eligible node:负责管理和配置集群,例如增加、删除节点相关动作。
- Data node:文档实际上就存储在数据节点,负责执行相关的操作, 例如CRUD、搜索、聚合等等操作
- Coordinating node:用于处理请求的路由、查询结果集的汇总、智能负载均衡..
- Ingest node:用于文档在indexing之前进行预处理
- Machine learning node:主要用于机器学习的任务,但是需要Basic License。
分片
如果有大量文档,由于内存限制、磁盘能力不足,无法快速响应请求,一个节点可能不够,这时数据可以分为较小的分片放在不同的服务器上。当查询的索引在不同的分片上,ES会把查询发送给每个相关的分片,并将结果组合在一起。
副本
为了提高吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,一个分片有零个或多个副本。
ES中可以有许多相同的分片,其中一个可以修改索引结构,该分片为主分片。当主分片丢失时,集群将副分片提升为主分片。
端口号
9300端口: ES节点之间通讯使用
9200端口: ES节点 和 外部 通讯使用
9300是TCP协议端口号,ES集群之间通讯端口号
9200端口号,暴露ES RESTful接口端口号
5.逻辑结构
数据在ES中是一个倒排索引表:
- 将要搜索的文档内容分词,所有不重复的词组成分词列表。
- 将搜索的文档最终以Document方式存储。
- 每个词都与Document关联。
- 生成一个“关键词-文档”形式的映射结构。
案例:
- 文档1:中国古代的精美散文(长文章已关键词进行排序)
- 文档2:古代精美散文作者
- 文档3:如何写出精美散文
词典集合:
| 单词ID | 单词 | 倒排列表 |
|---|---|---|
| 1 | 中国 | 1 |
| 2 | 古代 | 1,2 |
| 3 | 精美 | 1,2,3 |
| 4 | 散文 | 1,2,3 |
| 5 | 作者 | 2 |
| 6 | 如何 | 3 |
| 7 | 写出 | 2 |
分词器
standard分词器,默认分词器,对中文不友好。
IKAnalyzer: 免费开源的java分词器,目前比较流行的中文分词器之一。
需要注意ik插件的版本最好跟elasticsearch一致,不然要更改ik的配置。
更改方式:https://blog.csdn.net/Dongguabai/article/details/119932969
分词器设置
es支持创建索引和查询时分别使用不同的分词器
- analyzer,设置插入数据时的分词器
- search_analyzer,设置查询数据时的分词器,如果不指定,默认使用analyzer的分词器。
分词策略
ik_smart:做最粗力度的拆分,用于搜索,精确搜索。
共和国国歌会分成:共和国,国歌。
ik_max_word:最细粒度的拆分,最大化将文章内容分词。
共和国国歌会分成:共和国,共和,国,国歌。
字符串结构
text:会分词,不支持聚合、排序,支持模糊,精确查询。
keyword:不分词,支持聚合、排序,支持模糊,精确查询。
查询方式
term: 精确查询,对查询的值不分词,直接进倒排索引去匹配。 match:模糊查询,对查询的值分词,对分词的结果一一进入倒排索引去匹配
join查询
ES的连接查询有两种方式
nested
PUT index_test/type_info/1000 { "userId": 1000, "mobile": "13301020202", "nick": "梅西", "vipType": 1, "vipPoints": 1200, "regTime": "2018-06-18 12:00:31", "order": [ { "status": 1, "payMethod": 2, "amount": 100, "productCount": 3 }, { "status": 2, "payMethod": 2, "amount": 230, "productCount": 1 } ] }parent/child关联查询
- 创建索引时,父文档和子文档的字段都是在一个索引中。
- 一个父文档可以对应多个子文档。
- 父/子文档是完全独立的。父文档更新不会影响子文档,反之同理。
- 查询时:子查父: has_child,父查子:has_parent
- ES 中不支持类似的 JOIN 查询。即便 child aggregation 也不能做到像 SQL 那样的 JOIN 操作!
- 如果需求父文档和子文档的数据同时获取,需要先查询父文档数据,再查询子文档数据。
- 子文档的数据需要放在父文档同一个分片下
- children aggregation:对关联的 child 文档进行聚合操作
PUT test_info { "mappings": { "properties": { "contentType": { "type": "integer" }, "title": { "type": "text" }, "description": { "type": "text" }, "content": { "type": "text" }, "article_join": { //关联字段名称,自定义 "type": "join", //定义该字段为关联字段 "relations": { //定义父子关联字段匹配关系 "article": [ //父文档关联字段名 "category", //子文档关联字段名,可以一个父文档对应多个子文档,以数组排列 "author" ] } }, "categoryId": { //子文档字段 "type": "keyword" }, "categoryName": { //子文档字段 "type": "text" }, "authorId": { //子文档字段 "type": "keyword" }, "authorName": { //子文档字段 "type": "text" }, "authorDescription": {//子文档字段 "type": "text" }, "job": { //子文档字段 "type": "text" }, "topImage": { //子文档字段 "type": "keyword" } } } }
父文档插入数据:
PUT julang_article_info/_doc/1
{
"contentType": 3,
"title": "杭盖乐队:个性造就独一无二",
"description": "杭盖乐队:个性造就独一无二",
"content": "<p>禹国刚:追忆深交所创立缘起|致敬中国股市三十年</p>",
"publishTime": 1664091487,
"duration": "185.452",
"shareUrl": "images/qrcode/209_qrcode.png",
"haibao": "images/haibao/209_haibao.png",
"qrcode": "images/qrcode/209_qrcode.png",
"code":"分享code",
"article_join": {
"name": "article"
}
}子文档插入数据
PUT julang_article_info/_doc/category-1?routing=1 //需要放在同一个分片下
{
"categoryId": 111,
"categoryName": "测试视频标签1",
"article_join": {
"name":"category",
"parent":1 //父文档 _id
}
}
PUT julang_article_info/_doc/author-1?routing=1
{
"authorId": 111,
"authorName": "测试作者姓名1",
"authorDescription":"测试作者描述1",
"job":"测试作者工作1",
"topImage":"测试作者头像1",
"article_join": {
"name": "author",
"parent": 1
}
}查询子文档
GET julang_article_info/_search
{
"query": {
"has_parent": {
"parent_type": "article",
"query": {
"term": {
"_id": "1"
}
}
}
}
}主要区别:
- nested所有实体存储在一个type的文档中,parent-child模式,子type和父type存储在不同的文档里。
- 查询效率nested要高,但是在更新的时候,es会删除整个文档再创建,而parent-child只会删除更新的文档再创建,不影响其他文档。所以更新效率上parent-child要高。
使用场景:
- nested:少量子文档,并且不会经常改变的情况下使用。(用户消费流水)
- parent-child:大量子文档,频繁更新的情况下使用。(订单状态,物流信息)
使用建议:
慎用,不管是嵌套还是父子文档,以子数据为参数对嵌套或者父子文档数据聚合,都非常复杂,且性能低下。适用于以父数据为参数直接查询,不聚合操作。
6.部署
步骤:
//这里使用5.6.9版本较为合适
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.9.zip
unzip elasticsearch-5.6.9.zip
cd elasticsearch-5.6.9/
//ES在版本5以后不允许root用户启动,需手动创建用户
adduser elasticsearch
passwd elasticsearch
//将文件夹权限赋值给elasticsearch用户
chown -R elasticsearch /usr/local/elasticsearch-5.6.9
//切换用户
su elasticsearch
//启动es
./bin/elasticsearch -d
//检测是否启动
curl localhost:9200修改config/elasticsearch.yml文件,network.host值改为远程主机的IP
安装分词插件:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.6.9/elasticsearch-analysis-ik-5.6.9.zip重新启动Elastic便会加载这个插件
//该命令显示已安装的插件
curl localhost:9200/_cat/pluginsIK分词器的版本号,要与ES的版本一致,如不一致则无法启动。
如果不引入中文分词器,那么ES会默认将每一个中文都会进行分词,不会智能组词。
7.SpringBoot整合ES
在 elasticsearch 的官网上提供了两种 java 语言的 API ,一种是 Java Transport Client,一种是 Java REST Client。
**Java Transport Client是基于 TCP 协议交互的,**在 elasticsearch 7.0+ 版本后官方不再赞成使用,在Elasticsearch 8.0的版本中完全移除 TransportClient
**Java REST Client 是基于 HTTP 协议交互,**而 Java REST Client 又分为 Java Low Level REST Client 和 Java High Level REST Client
Java High Level REST Client 是在 Java Low Level REST Client 的基础上做了封装,使其以更加面向对象和操作更加便利的方式调用 elasticsearch 服务。
es 8.x 中废弃了
RestHighLevelClient,使用新版的java api client,但是spring data elasticsearch还未更新到该版本.所以需要兼容es 8.x。 初始化需引入new RestHighLevelClientBuilder(httpClient).setApiCompatibilityMode(true).build();
QueryBuilder (Java High Level REST Cilent)
QueryBuilder 主要用来构建查询条件、过滤条件,SortBuilder主要是构建排序。
要构建QueryBuilder ,我们可以使用工具类QueryBuilders,主要是它的实现类BoolQueryBuilder 。里面有大量的方法用来完成各种各样的QueryBuilder的构建,字符串的、Boolean型的、match的、地理范围的等等。
要构建SortBuilder,可以使用SortBuilders来完成各种排序。
然后就可以通过NativeSearchQueryBuilder来组合这些QueryBuilder和SortBuilder,再组合分页的参数等等,最终就能得到一个SearchQuery了。
8.可视化工具(Kibana)
需要与es版本一致,否则报错。
修改kibana.yml中远程地址,连接远程ip的ElasticSearch。
elasticsearch.url: "http://81.70.31.48:8085"
数据操作
创建索引
shell# 语法: PUT /<index> # 示例: PUT /laowang创建数据
shell# 语法 PUT /<index>/_doc/<_id> POST /<index>/_doc/ PUT /<index>/_create/<_id> POST /<index>/_create/<_id> index:索引名称,如果索引不存在,会自动创建 _doc:类型 <_id>:唯一识别符,创建一个数据时,可以自定义ID,也可以让他自动生成 # ES 存储数据三个必要构成条件,每一条数据必须有以上的数据结构 # 示例: PUT /student/user/4 { "name":"congtianqi", "sex":"male" }简单查询
shell# 查看所有索引信息 GET /_all GET _all # 查看所有索引的数据 GET /_all/_search # 查看指定索引信息 GET /student # 查看指定索引的数据 GET /student/_search # 查看指定数据 GET /student/user/1条件查询
shell# 可以省略 value 行,与 Key 合并到一行 GET /news/_search { "query": { "term": { <-------- 使用 term 匹配,适用于精确查找 "title":"北京烤鸭" <------- 简写,并为一行 } } } # 方法二: GET /news/_search { "query": { "match": { <-------- 使用 match 匹配,适用于模糊查找 "title": "北京烤鸭" } } }修改数据
shell# 注意,修改数据时,除了要修改的值,其他字段的值也要带上,否则原有的其他字段会丢失 PUT /student/user/2 { "name":"wqh", "gender":"male", "age":"19" }